Git 常用语句与命令行
Git 常用语句与命令行
Git 是什么
git,是一个分布式版本控制软件,最初目的是为更好地管理Linux内核开发而设计
分布式版本控制系统的客户端并不只提取最新版本的文件快照,而是把代码仓库完整地镜像下来。这么一来,任何一处协同工作用的服务器发生故障,事后都可以用任何一个镜像出来的本地仓库恢复
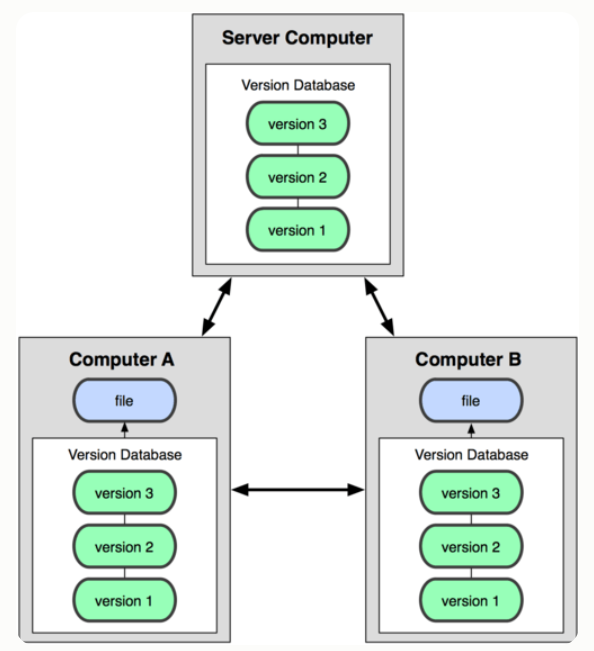
项目开始,只有一个原始版仓库,别的机器可以clone这个原始版本库,那么所有clone的机器,它们的版本库其实都是一样的,并没有主次之分
所以在实现团队协作的时候,只要有一台电脑充当服务器的角色,其他每个人都从这个“服务器”仓库clone一份到自己的电脑上,并且各自把各自的提交推送到服务器仓库里,也从服务器仓库中拉取别人的提交
github实际就可以充当这个服务器角色,其是一个开源协作社区,提供Git仓库托管服务,既可以让别人参与你的开源项目,也可以参与别人的开源项目
工作原理
当我们通过git init创建或者git clone一个项目的时候,项目目录会隐藏一个.git子目录,其作用是用来跟踪管理版本库的
Git 中所有数据在存储前都计算校验和,然后以校验和来引用,所以在我们修改或者删除文件的时候,git能够知道
Git用以计算校验和的机制叫做 SHA-1 散列(hash,哈希), 这是一个由 40 个十六进制字符(0-9 和 a-f)组成字符串,基于 Git 中文件的内容或目录结构计算出来,如下:
24b9da6552252987aa493b52f8696cd6d3b00373
当我们修改文件的时候,git就会修改文件的状态,可以通过git status进行查询,状态情况如下:
- 已修改(modified):表示修改了文件,但还没保存到数据库中。
- 已暂存(staged):表示对一个已修改文件的当前版本做了标记,使之包含在下次提交的快照中。
- 已提交(committed):表示数据已经安全的保存在本地数据库中。
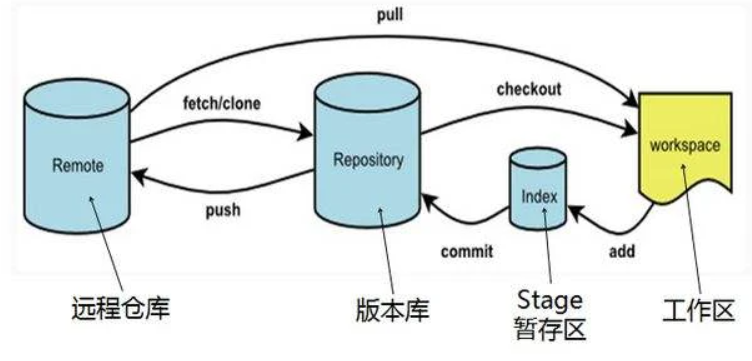
文件状态对应的,不同状态的文件在Git中处于不同的工作区域,主要分成了四部分:
- 工作区:相当于本地写代码的区域,如 git clone 一个项目到本地,相当于本地克隆了远程仓库项目的一个副本
- 暂存区:暂存区是一个文件,保存了下次将提交的文件列表信息,一般在 Git 仓库目录中
- 本地仓库:提交更新,找到暂存区域的文件,将快照永久性存储到 Git 本地仓库
- 远程仓库:远程的仓库,如 github
HEAD、工作树和索引
在git中,可以存在很多分支,其本质上是一个指向commit对象的可变指针,而Head是一个特别的指针,是一个指向你正在工作中的本地分支的指针
简单来讲,就是你现在在哪儿,HEAD 就指向哪儿
例如当前我们处于master分支,所以HEAD这个指针指向了master分支指针

然后通过调用git checkout test切换到test分支,那么HEAD则指向test分支,如下图:
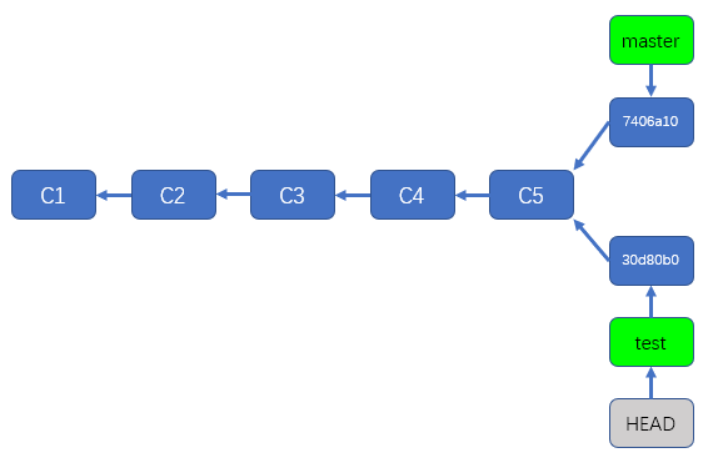
但我们在test分支再一次commit信息的时候,HEAD指针仍然指向了test分支指针,而test分支指针已经指向了最新创建的提交,如下图:
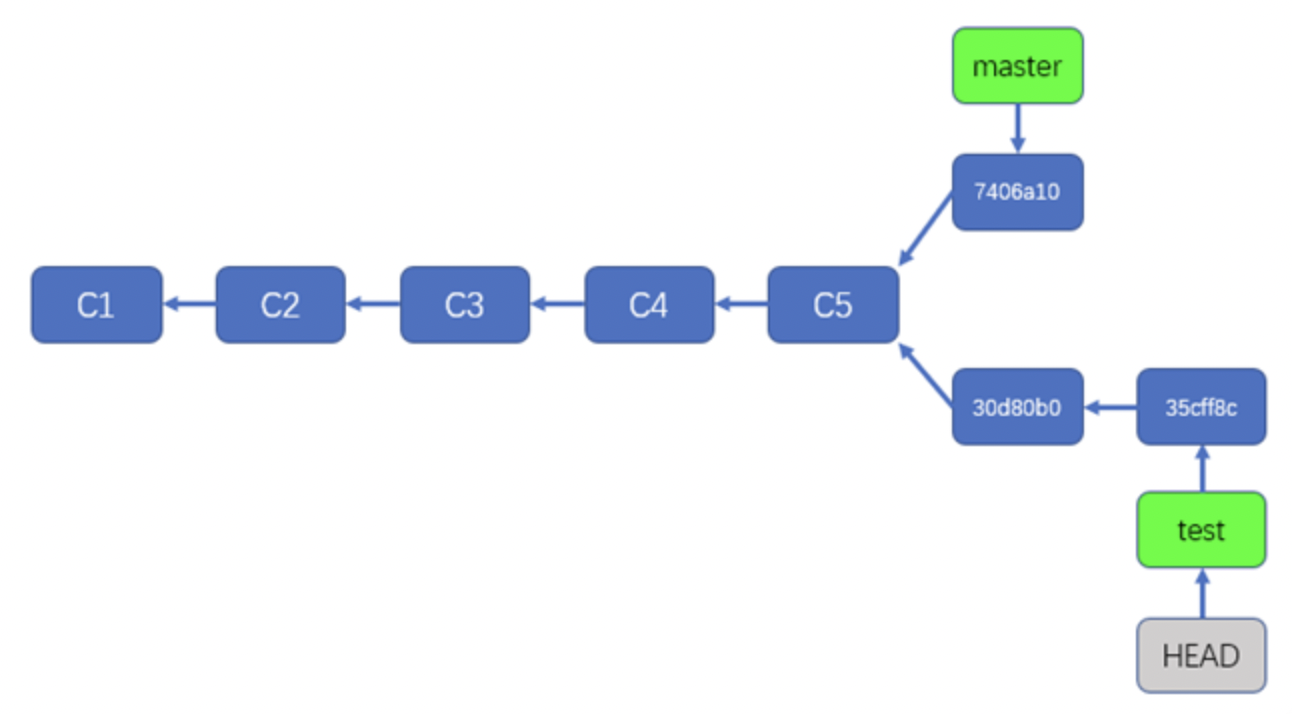
这个HEAD存储的位置就在.git/HEAD目录中,查看信息可以看到HEAD指向了另一个文件
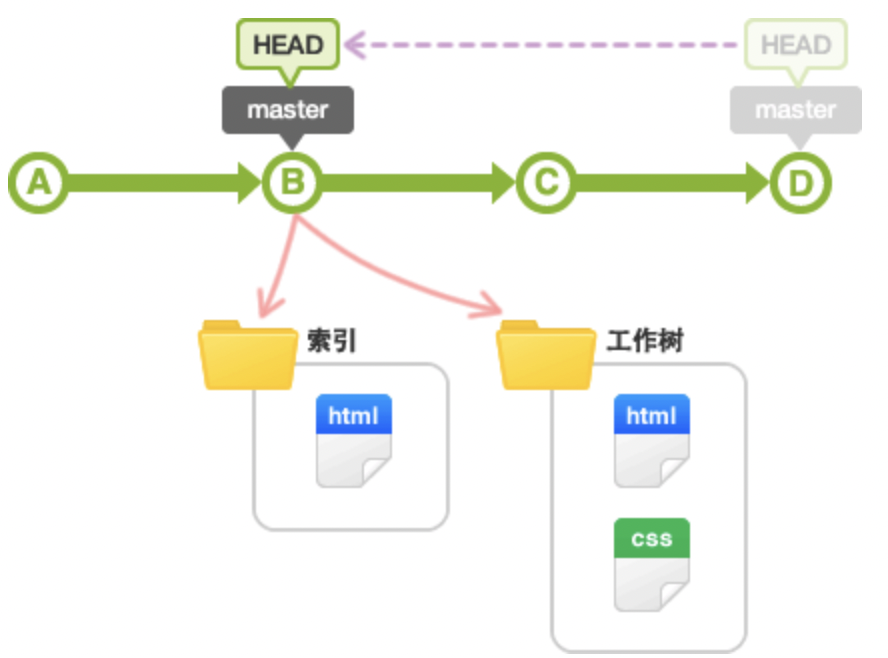
工作树和索引
在Git管理下,大家实际操作的目录被称为工作树,也就是工作区域。在数据库和工作树之间有索引,索引是为了向数据库提交作准备的区域,也被称为暂存区域
Git在执行提交的时候,不是直接将工作树的状态保存到数据库,而是将设置在中间索引区域的状态保存到数据库。
因此,要提交文件,首先需要把文件加入到索引区域中。
所以,凭借中间的索引,可以避免工作树中不必要的文件提交,还可以将文件修改内容的一部分加入索引区域并提交。
常用语句
新建(初始化)项目
初始化当前项目
git init
新建一个目录,将其初始化为Git代码库
git init [project-name]
在指定目录创建一个空的 Git 仓库。运行这个命令会创建一个名为 directory,只包含 .git 子目录的空目录。
git init --bare <directory>
下载一个项目和它的整个代码历史
这个命令就是将一个版本库拷贝到另一个目录中,同时也将分支都拷贝到新的版本库中。这样就可以在新的版本库中提交到远程分支
git clone [url]
修改配置项
显示当前的Git配置
git config --list
编辑Git配置文件
git config -e [--global]
输出、设置基本的全局变量(用户名、邮箱)
git config --global user.email
git config --global user.name
git config --global user.email "MyEmail@gmail.com"
git config --global user.name "My Name"
获取信息
显示commit历史,以及每次commit发生变更的文件
git log --stat
搜索提交历史,根据关键词
git log -S [keyword]
状态信息
显示分支,未跟踪文件,更改和其他不同
git status
log、提交信息等
显示commit历史,以及每次commit发生变更的文件
git log --stat
搜索提交历史,根据关键词
git log -S [keyword]
显示某个commit之后的所有变动,每个commit占据一行
git log [tag] HEAD --pretty=format:%s
显示某个文件的版本历史,包括文件改名
git log --follow [file]
git whatchanged [file]
显示指定文件相关的每一次diff
git log -p [file]
显示过去5次提交
it log -5 --pretty --oneline
分支操作
创建新的分支
git br <new_branch>
查看远程分支
git br -r
查看已经被合并到当前分支的分支
git br --merged
查看尚未被合并到当前分支的分支
git br --no-merged
常见问题
merge 和 reabse 的区别
git rebase 与 git merge都有相同的作用,都是将一个分支的提交合并到另一分支上,但是在原理上却不相同
git merge
通过git merge将当前分支与xxx分支合并,产生的新的commit对象有两个父节点
如果“指定分支”本身是当前分支的一个直接子节点,则会产生快照合并
举个例子,bugfix分支是从master分支分叉出来的,如下所示:
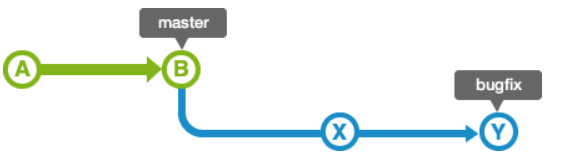
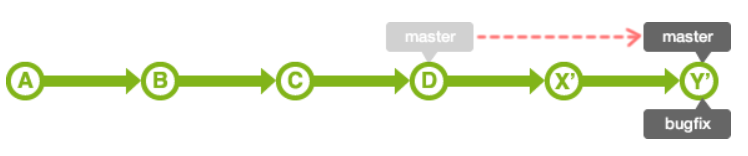
合并bugfix分支到master分支时,如果master分支的状态没有被更改过,即 bugfix分支的历史记录包含master分支所有的历史记录
所以通过把master分支的位置移动到bugfix的最新分支上,就完成合并
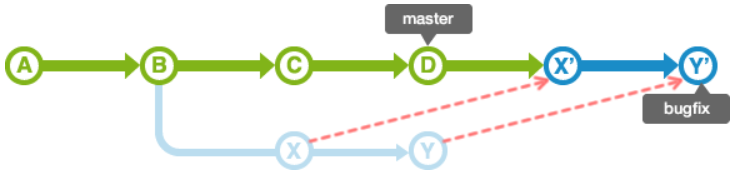
如果master分支的历史记录在创建bugfix分支后又有新的提交,如下情况:
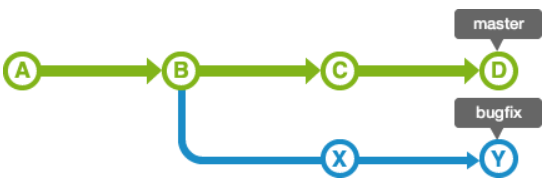
这时候使用git merge的时候,会生成一个新的提交,并且master分支的HEAD会移动到新的分支上,如下:

从上面可以看到,会把两个分支的最新快照以及二者最近的共同祖先进行三方合并,合并的结果是生成一个新的快照
git rebase
同样,master分支的历史记录在创建bugfix分支后又有新的提交,如下情况:
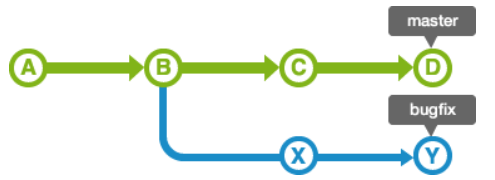
通过git rebase,会变成如下情况:
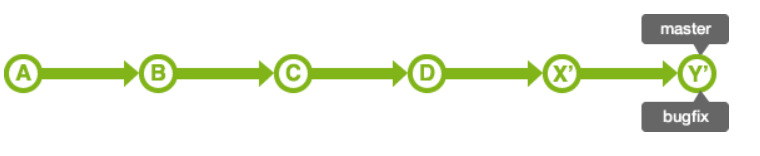
在移交过程中,如果发生冲突,需要修改各自的冲突,如下:
rebase之后,master的HEAD位置不变。因此,要合并master分支和bugfix分支
从上面可以看到,rebase会找到不同的分支的最近共同祖先,如上图的B,然后对比当前分支相对于该祖先的历次提交,提取相应的修改并存为临时文件(老的提交X和Y也没有被销毁,只是简单地不能再被访问或者使用),然后将当前分支指向目标最新位置D, 然后将之前另存为临时文件的修改依序应用。
区别
git merge 会让2个分支的提交按照提交时间进行排序,并且会把最新的2个commit合并成一个commit,使得最后的分支树呈现非线性的结构
git reabse 将当前的提交复制到master的最新提交之后,最终形成一个线性的分支树
社区评价:
这个看公司需求,因为有些时候,注重提交日志的话,那我们应该选择merge,这样每一次的提交都清清楚楚记录着,如果说,我们不太注重日志的记录,那rebase是可以的,但是rebase有一个小小的缺点,就是基点变了,提交的多了,就不知道怎么是从哪个分支拉取的代码了
rebase 空间消耗小,merge责任清晰。收验pr用merge更好。自己上传前校验和处理与仓库的冲突,rebase更好。
常用可视化工具
Webstorm、vscode 内置git可视化工具,TortoiseGit 小乌龟
Git中 fork, clone,branch这三个概念,有什么区别?
fork 只能对代码仓进行操作,且 fork 不属于 git 的命令,通常用于代码仓托管平台的一种“操作” clone 是 git 的一种命令,它的作用是将文件从远程代码仓下载到本地,从而形成一个本地代码仓 branch 特征与 fork 很类似,fork 得到的是一个新的、自己的代码仓,而 branch 得到的是一个代码仓的一个新分支
说说你对git stash 的理解?应用场景?
stash,译为存放,在 git 中,可以理解为保存当前工作进度,会把暂存区和工作区的改动进行保存,这些修改会保存在一个栈上
后续你可以在任何时候任何分支重新将某次的修改推出来,重新应用这些更改的代码
默认情况下,git stash会缓存下列状态的文件:
- 添加到暂存区的修改(staged changes)
- Git跟踪的但并未添加到暂存区的修改(unstaged changes)
但以下状态的文件不会缓存:
- 在工作目录中新的文件(untracked files)
- 被忽略的文件(ignored files)
如果想要上述的文件都被缓存,可以使用-u或者--include-untracked可以工作目录新的文件,使用-a或者--all命令可以当前目录下的所有修改
常见命令:
- git stash
- git stash save
- git stash list
- git stash pop
- git stash apply
- git stash show
- git stash drop
- git stash clear
应用场景:
当你在项目的一部分上已经工作一段时间后,所有东西都进入了混乱的状态, 而这时你想要切换到另一个分支或者拉下远端的代码去做一点别的事情
但是你创建一次未完成的代码的commit提交,这时候就可以使用git stash
例如以下场景:
当你的开发进行到一半,但是代码还不想进行提交 ,然后需要同步去关联远端代码时.如果你本地的代码和远端代码没有冲突时,可以直接通过git pull解决
但是如果可能发生冲突怎么办.直接git pull会拒绝覆盖当前的修改,这时候就可以依次使用下述的命令:
- git stash
- git pull
- git stash pop
或者当你开发到一半,现在要修改别的分支问题的时候,你也可以使用git stash缓存当前区域的代码
- git stash:保存开发到一半的代码
- git commit -m '修改问题'
- git stash pop:将代码追加到最新的提交之后
说说你对git reset 和 git revert 的理解?区别?
git reset
reset用于回退版本,可以遗弃不再使用的提交
执行遗弃时,需要根据影响的范围而指定不同的参数,可以指定是否复原索引或工作树内容
git revert
在当前提交后面,新增一次提交,抵消掉上一次提交导致的所有变化,不会改变过去的历史,主要是用于安全地取消过去发布的提交